Python列表,元组,字典,数组,set,struct
本文摘录有关python数据类型的内容
列表:可变
列表可以使用所有适用于序列的标准操作,例如索引、分片、连接和乘法。本文介绍一些可以改变列表的方法。
列表简介
列表(list)是Python以及其他语言中最常用到的数据结构之一。Python使用使用中括号 [ ] 来解析列表。列表是可变的(mutable)——可以改变列表的内容。
list 函数
通过 list(seq) 函数把一个序列类型转换成一个列表。
>>> list('hello')
['h', 'e', 'l', 'l', 'o']]
list 函数使用于所有类型的序列,而不只是字符串。
改变列表:元素赋值
使用索引标记来为某个特定的、位置明确的元素赋值。
>>> x = [1, 1, 1]
>>> x[1] = 2
>>> x
[1, 2, 1]
不能为一个位置不存在的元素进行赋值。
删除元素
>>> names = ['Alice', 'Beth', 'Cecil', 'Dee-Dee', 'Earl']
>>> del names[2]
>>> names
['Alice', 'Beth', 'Dee-Dee', 'Earl']
除了删除列表中的元素,del 语句还能用于删除其他元素。
分片赋值
>>> name = list('Perl')
>>> name
['P', 'e', 'r', 'l']
>>> name[2:] = list('ar')
>>> name
['P', 'e', 'a', 'r']
在使用分片赋值时,可以使用与原序列不等长的序列将分片替换:
>>> name = list('Perl')
>>> name[1:] = list('ython')
>>> name
['P', 'y', 't', 'h', 'o', 'n']
分片赋值语句可以在不需要替换任何原有元素的情况下插入新的元素。
>>> numbers = [1, 5]
>>> numbers[1:1] = [2, 3, 4]
>>> numbers
[1, 2, 3, 4, 5]
通过分片赋值来删除元素也是可行的。
>>> numbers
[1, 2, 3, 4, 5]
>>> numbers[1:4] = []
>>> numbers
[1, 5]
列表方法
方法是一个与某些对象有紧密联系的函数。一般,方法可以这样进行调用:
对象.方法(参数)
除了对象被放置到方法名之前,并且两者之间用一个点号隔开。
append
append方法用于在列表末尾追加新的对象:
>>> lst = [1, 2, 3]
>>> lst.append(4)
>>> lst
[1, 2, 3, 4]
append方法和其他一些方法类似,只是在恰当位置修改原来的列表。这意味着,它不是简单地返回一个修改过的新列表——而是直接修改原来的列表。
count
count 方法统计某个元素在列表中出现的次数:
>>> ['to', 'be', 'or', 'not', 'to', 'be'].count('to')
2
>>> x = [[1,2], 1, 1, [2, 1, [1, 2]]]
>>> x.count(1)
2
>>> x.count([1,2])
1
extend
extend 方法可以在列表的末尾一次性追加另一个序列中的多个值。
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> a.extend(b)
>>> a
[1, 2, 3, 4, 5, 6]
extend 方法修改了被扩展的列表,而原始的连接操作(+)则不然,它会返回一个全新的列表。
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> a.extend(b)
>>> a
[1, 2, 3, 4, 5, 6]
>>>
>>> a + b
[1, 2, 3, 4, 5, 6, 4, 5, 6]
>>> a
[1, 2, 3, 4, 5, 6]
index
index 方法用于从列表中找出某个值第一个匹配项的索引位置:
>>> knights = ['We', 'are', 'the', 'knights', 'who', 'say', 'ni']
>>> knights.index('who')
4
当搜索不存在的值时,就会引发一个异常。
insert
insert 方法用于将对象插入到列表中:
>>> numbers = [1, 2, 3, 5, 6, 7]
>>> numbers.insert(3, 'four')
>>> numbers
[1, 2, 3, 'four', 5, 6, 7]
pop
pop 方法会移除列表中的一个元素(默认是最后一个),并且返回该元素的值:
>>> x = [1, 2, 3]
>>> x.pop()
3
>>> x
[1, 2]
>>> x.pop(0)
1
>>> x
[2]
pop方法是唯一一个即能修改列表又返回元素值(除了None)的列表方法。
remove
remove 方法用于移除列表中某个值的第一个匹配项:
>>> x = ['to', 'be', 'or', 'not', 'to', 'be']
>>> x.remove('be')
>>> x
['to', 'or', 'not', 'to', 'be']
>>> x.remove('bee')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: list.remove(x): x not in list
只有第一次出现的值被移除,而不存在与列表中的值是不会移除的。
remove 是一个没有返回值的原位置改变方法。它修改了列表却没有返回值。
reverse
reverse 方法将列表中的元素反向存放。
>>> x = [1, 2, 3]
>>> x.reverse()
>>> x
[3, 2, 1]
该方法改变了列表但不返回值。
sort
sort 方法用于在原位置对列表进行排序。
>>> x = [4, 6, 2, 1, 7, 9]
>>> x.sort()
>>> x
[1, 2, 4, 6, 7, 9]
sort 方法修改了 x 却返回了空值。
元组:不可变序列
创建元组的语法很简单:如果你用逗号分隔了一些值,那么你就自动创建了元组。
>>> 1, 2, 3
(1, 2, 3)
元组也是(大部分时候是)通过圆括号括起来的:
>>> (1,2,3)
(1, 2, 3)
实现包括一个值的元组有些奇特——必须加个逗号:
>>> 42,
(42,)
>>> (42,)
(42,)
tuple函数的功能与list函数基本上是一样的:以一个序列作为参数并把它转化为元组。
>>> tuple([1, 2, 3])
(1, 2, 3)
- 除了创建元组和访问元组元组之外,也没有太多其他操作,可以参考其他类型的序列来实现。
元组的意义:元组可以在映射(和集合的成员)中当作键使用——而列表则不行;元组作为很多内建函数和方法的返回值存在。*
字典:可变
可存储任意类型对象,如字符串、数字、元组等其他容器模型。
创建字典
字典由键和对应值成对组成。字典也被称作关联数组或哈希表。基本语法如下:
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
也可如此创建字典:
dict1 = { 'abc': 456 };
dict2 = { 'abc': 123, 98.6: 37 };
每个键与值用冒号隔开(:),每对用逗号,每对用逗号分割,整体放在花括号中({})。
键必须独一无二,但值则不必。
值可以取任何数据类型,但必须是不可变的,如字符串,数或元组。
访问字典里的值
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
print "dict['Name']: ", dict['Name'];
print "dict['Age']: ", dict['Age'];
以上实例输出结果:
dict['Name']: Zara
dict['Age']: 7
如果用字典里没有的键访问数据,会输出错误KeyError: 'Alice'[/code]
修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
dict['Age'] = 8; # update existing entry
dict['School'] = "DPS School"; # Add new entry
print "dict['Age']: ", dict['Age'];
print "dict['School']: ", dict['School'];
以上实例输出结果:
dict['Age']: 8
dict['School']: DPS School
删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显示删除一个字典用del命令,如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
del dict['Name']; # 删除键是'Name'的条目
dict.clear(); # 清空词典所有条目
del dict ; # 删除词典
print "dict['Age']: ", dict['Age'];
print "dict['School']: ", dict['School'];
但这会引发一个异常,因为用del后字典不再存在:dict['Age']:
#Traceback (most recent call last):
# File "test.py", line 8, in
# print "dict['Age']: ", dict['Age'];
#TypeError: 'type' object is unsubscriptable
字典键的特性
字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Name': 'Manni'}; print "dict['Name']: ", dict['Name']; #输出结果: #dict['Name']: Manni键必须不可变,所以可以用数,字符串或元组充当,所以用列表就不行,如下实例:
dict = {['Name']: 'Zara', 'Age': 7}; print "dict['Name']: ", dict['Name']; #输出结果: #Traceback (most recent call last): # File "test.py", line 3, in <module> # dict = {['Name']: 'Zara', 'Age': 7}; #TypeError: list objects are unhashable
Array数组:固定类型
array模块定义了一种序列数据结构,看起来和list很相似,但是所有成员必须是相同基本类型。
array作用是高效管理固定类型数值数据的序列。
初始化
array实例化可以提供一个参数来描述允许那种数据类型,还可以有一个初始的数据序列存储在数组中。
import array
import binascii
s = 'This is the array.'
a = array.array('c', s)
print 'As string:', s
print 'As array :', a
print 'As hex :', binascii.hexlify(a)
输出结果:
As string: This is the array.
As array : array('c', 'This is the array.')
As hex : 54686973206973207468652061727261792e
处理数组
类似于其他python序列,可以采用同样方式扩展和处理array。
import array
import pprint
a = array.array('i', xrange(3))
print 'Initial :', a
a.extend(xrange(3))
print 'Extended:', a
print 'slice: :', a[2:5]
print 'Itetator:'
print list(enumerate(a))
输出结果:
Initial : array('i', [0, 1, 2])
Extended: array('i', [0, 1, 2, 0, 1, 2])
slice: : array('i', [2, 0, 1])
Itetator:
[(0, 0), (1, 1), (2, 2), (3, 0), (4, 1), (5, 2)]
数组和文件
可以使用高效读/写文件的专用内置方法将数组的内容写入文件或从文件读取数组。
import array
import binascii
import tempfile
a = array.array('i', xrange(5))
print 'A1: ',a
output = tempfile.NamedTemporaryFile()
a.tofile(output.file)
output.flush
with open(output.name, 'rb') as input:
raw_input = input.read()
print 'Raw Contents:', binascii.hexlify(raw_data)
input.seek(0)
a2 = array.array('i')
a2.fromfile(input, len(a))
print 'A2: ', a2
候选字节顺序
如果数组中的数据没有采用固有的字节顺序,或者在发送到一个采用不同字节顺序的系统前需要交换顺序,可以在python转换整个数组而无须迭代处理每个元素。
import array
import binascii
def to_hex(a):
chars_per_item = a.itemsize * 2
hex_version = binascii.hexlify(a)
num_chunks = len(hex_version) / chars_per_item
for i in xrange(num_chunks):
start = i * chars_per_item
end = start + chars_per_item
yield hex_version[start:end]
a1 = array.array('i', xrange(5))
a2 = array.array('i', xrange(5))
a2.byteswap()
fmt = '%10s %10s %10s %10s'
print fmt % ('A1_hex', 'A1', 'A2_hex', 'A2')
print fmt % (('-' * 10,) * 4)
for value in zip(to_hex(a1), a1, to_hex(a2), a2):
print fmt % value
byteswap()会交换C数组中元素的字节顺序,比在python中循环处理数据高效的多。
输出结果:
A1_hex A1 A2_hex A2
---------- ---------- ---------- ----------
00000000 0 00000000 0
01000000 1 00000001 16777216
02000000 2 00000002 33554432
03000000 3 00000003 50331648
04000000 4 00000004 67108864
Set:集合
python的set和其他语言类似, 是一个无序不重复元素集, 基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交), difference(差)和sysmmetric difference(对称差集)等数学运算.
sets 支持 x in set, len(set),和 for x in set。作为一个无序的集合,sets不记录元素位置或者插入点。因此,sets不支持 indexing, slicing, 或其它类序列(sequence-like)的操作。
基本的操作:
set.add('x') #添加一项
set.update([10, 3, 32]) # 添加更多项
set.remove('x') #删掉一项
len(s) #长度
判断元素:
x in set #判断是否在里面
s.issubset(t) #测试是否 s 中的每一个元素都在 t 中
s.issuperset(t) #测试是否 t 中的每一个元素都在 s 中
简单应用:
x = set('spam')
y = set(['h','a','m'])
print x,y
运行结果:
(set(['a', 'p', 's', 'm']), set(['a', 'h', 'm']))
求交集,并集,差集:
print x & y
print x | y
print x -y
结果就不列出来了。
使用set去除list里面的重复元素:
a = [11,22,33,44,11,22]
b = set(a)
print b
c = [i for i in b]
print c
运行结果:
set([33, 11, 44, 22])
[33, 11, 44, 22]
struct:打包为c结构体
struct结构体在c语言中的作用,它定义了一种结构,里面包含不同类型的数据(int,char,bool等等),方便对某一结构对象进行处理。
而在网络通信当中,大多传递的数据是以二进制流(binary data)存在的。当传递字符串时,不必担心太多的问题,而当传递诸如int、char之类的基本数据的时候,就需要有一种机制将某些特定的结构体类型打包成二进制流的字符串然后再网络传输,而接收端也应该可以通过某种机制进行解包还原出原始的结构体数据。
python中的struct模块就提供了这样的机制,该模块的主要作用就是对python基本类型值与用python字符串格式表示的C struct类型间的转化
简单例子:
import struct
import binascii
values = (1, 'abc', 2.7)
s = struct.Struct('I3sf')
packed_data = s.pack(*values)
unpacked_data = s.unpack(packed_data)
print 'Original values:', values
print 'Format string :', s.format
print 'Uses :', s.size, 'bytes'
print 'Packed Value :', binascii.hexlify(packed_data)
print 'Unpacked Type :', type(unpacked_data), ' Value:', unpacked_data
输出:
Original values: (1, 'abc', 2.7)
Format string : I3sf
Uses : 12 bytes
Packed Value : 0100000061626300cdcc2c40
Unpacked Type : <type 'tuple'> Value: (1, 'abc', 2.700000047683716)
对应的c结构体: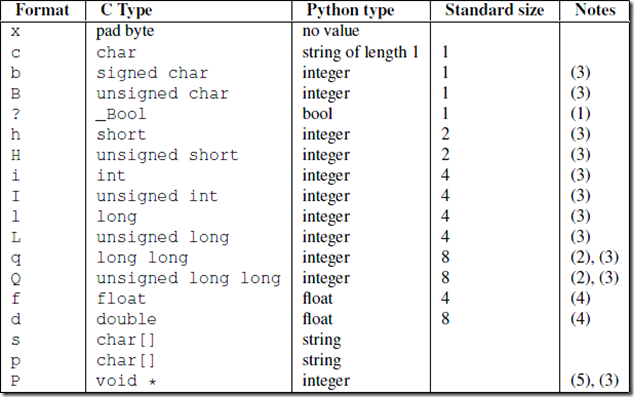
另一方面,打包的后的字节顺序默认上是由操作系统的决定的,当然struct模块也提供了自定义字节顺序的功能,可以指定大端存储、小端存储等特定的字节顺序
不同的字节顺序和存储方式也会导致字节大小的不同。在format字符串前面加上特定的符号即可以表示不同的字节顺序存储方式,例如采用小端存储:
s = struct.Struct(‘<I3sf’)

将列表打包为结构体
import struct
a=[1,2,3,4]
len_a=len(a)
s=struct.pack("{0}B".format(len_a),*a)
print repr(s)
# '\x1\x2\x3\x4'
这里用到了一个小把戏,string类的format格式化,详见python参考手册,相当于把pack的第一个形参的d前面替换成4d,非常方便。
下列两个是等效的
'<{0}B'.format(4)
'<4B'
测试其它
# string 带有*args的格式化
print '{0}, {1}, {2}'.format('a', 'b', 'c')
# 'a, b, c'
print 'GPS: {latitude},{longitude}'.format(latitude='37.24N',longitude='-115.81W')
# 'GPS: 37.24N, -115.81W'
多重循环
a = ['a1', 'a2', 'a3']
b = ['b1', 'b2']
# will iterate 3 times,
# the last iteration, b will be None
print "Map:"
for x, y in map(None, a, b):
print x, y
# will iterate 2 times,
# the third value of a will not be used
print "Zip:"
for x, y in zip(a, b):
print x, y
# will iterate 6 times,
# it will iterate over each b, for each a
# producing a slightly different outpu
print "List:"
for x, y in [(x,y) for x in a for y in b]:
print x, y